오늘은 Llama 3.2 모델의 파인 튜닝을 위한 준비 작업인 인공지능 모델 다운 및 설치에 관해 이야기해 보려 합니다.
Llama 3.2 모델 파인 튜닝을 위한 준비 작업
이전 글에서 llama 3.1 모델을 다운로드하고 설치하여 실행하는 간단한 방법 중 하나로 Ollama 플랫폼을 이용하는 방법에 대해 이야기해 봤습니다.
이를 간단히 요약하자면, Ollama 홈페이지를 통해 Ollama 플랫폼을 자신의 PC에 설치를 하고 역시 홈페이지를 통해 Ollama에서 제공하는 인공지능 모델명을 확인한 후 윈도우 cmd를 열어서 "ollama run [모델명]"을 입력하여 다운로드 및 설치 후 실행을 동시에 수행하면 됩니다.
자세한 내용은 아래 이전 글을 확인해 보세요.
Meta AI의 Llama3.1 다운로드 및 설치 방법 그리고 WebUI 1of2
오늘 라마 3.1(Llama3.1)을 직접 설치해 보고 앞으로 계속 사용해야 하므로 환경 설정을 어떻게 해야 조금 더 편리하게 사용할지 한번 준비해 보도록 하겠습니다. 지난 7월 23일(현지시각) 과거 페이
paulsmedia.tistory.com
하지만, 이렇게 설치된 llama 3.1 모델은 ollama를 통해 실행하거나 WebUI를 이용해서 문자를 주고받는 정도까지는 편리한 기능을 제공하고 있으나, 파인 튜닝과 같이 모델 자체를 변형을 하는 것은 불가능하더군요. ollama api를 찾아봐도 지원하지 않았습니다.
때문에 llama 공식 홈페이지에서 모델을 직접 다운로드 하거나, 역시 공식적인 모델이나 Hugging face를 통해 모델을 다운로드 해야하죠.
하지만, 여기에서 또 문제가 있어요. 그동안 우리가 또는 최소한 이 블로그에서 다루었던 텐서플로우, 딥러닝 방법들은 거의 무도 Hugging face의 transformers 라이브러리와 관련되어 있죠. 때문에 직접적으로 모델을 핸들링 하기에는 Hugging face에서 다운로드하는 mode.safetensors 를 이용하는 것이 보다 익숙합니다. 이게 또 하나의 문제가 되는 것이 그럼 이 모델이 정상적으로 작동하는 모델인가를 체크해 보기 위해서는 또 다른 작업이 있어야만 해요. 이미 설치했던 Ollama 플랫폼을 바로 이용할 수 있으면 편할 텐데 말이에요.
더불어 우리는 이전 글에서 ollama를 통해 설치된 llama 모델과 콘솔을 이용해 대화하는 것이 불편하고 히스토리도 남아 있지 않기에 웹UI 형식으로 가능한 챗GPT와 유사한 WebUI를 구성하여 좀 더 편리한 방법의 대화창 구축에 대해 정리한 적이 있습니다. 자세한 내용은 아래 링크를 참고하면 되고요,
Meta AI의 Llama3.1 다운로드 및 설치 방법 그리고 WebUI 2of2
지난번 글에 이어서 오늘은 Meta의 라마 3.1(llama 3.1)과 터미널에서 대화는 것 이외 챗GPT와 비슷하게 WebUI를 이용하여 편리하게 대화할 수 있는 환경 설정에 대해 살펴보겠습니다.llama 3.1을 위한 Open
paulsmedia.tistory.com
때문에, 파인 튜닝을 위해 Hugging face를 통해 다운로드한 llama 모델 "model.safetensors" 파일을 Ollama 플랫폼에 이식시킬 수만 있다면 이전까지 정리한 내용을 바로 적용할 수 있을 거예요.
Ollama로 이식하기 위한 GGUF 파일 형식 변환
그 방법은 의외로 간단했어요. 바로 GGUF 포멧을 사용하면 ollama 플랫폼에 모델을 이식할 수 있다고 합니다.
GGUF (Generalized GPT Utility Format)는 상대적으로 최근에 등장한 언어 모델 포맷(형식)이라고 하더라고요. LLM 분야의 저문가인 Georgi Gerganov 이라고 하는 개발자가 이 포맷을 최초로 개발했다고 합니다. 해당 분야의 꽤 유명인 같더라고요.
이 사람이 llama 모델이 GPU를 사용하지 않아도 다양한 플랫폼 그러니까 GPU가 없는 윈도우 등 다양한 OS에서 llama가 동작하도록 llama.cpp라는 프로젝트로 구현했다고 해요.
하여간, Hugging face에 모델을 다운로드 하면 mode.safetensors 포맷인데, 이를 llama.cpp를 이용하여 *.gguf 포맷으로 변환이 가능합니다.
그럼 단계별로 정리해 보겠습니다.
Hugging Face 모델 다운로드
Hugging Face에서 원하는 모델을 다운로드합니다. 이때 `model.safetensors`, `config.json`, `tokenizer.json` 등의 파일이 필요합니다. 다운로드는 `huggingface_hub` 라이브러리의 `snapshot_download` 함수를 사용하여 수행할 수 있습니다.
from huggingface_hub import snapshot_download
model_id = "모델_ID" # 예: "gemmathon/gemma-pro-3.1b-ko-v0.5_plus"
snapshot_download(repo_id=model_id, local_dir="모델_저장_경로", local_dir_use_symlinks=False, revision="main")또는, hugging face의 공식 페이지에서 해당 파일들을 직접 다운로드하여 임의의 폴더에 저장한 후 사용할 수도 있습니다.
GGUF 형식으로 변환
Ollama는 GGUF 형식의 모델을 지원하므로, 다운로드한 `model.safetensors` 파일을 GGUF 형식으로 변환해야 합니다. 이를 위해 `llama.cpp` 도구를 사용합니다.
- `llama.cpp` 저장소를 클론하고 필요한 요구 사항을 설치합니다.
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
pip install -r requirements.txt
- `convert_hf_to_gguf.py` 스크립트를 사용하여 변환을 수행합니다.
python convert_hf_to_gguf.py 모델_저장_경로 --outfile 변환된_모델_경로/모델명.gguf --outtype 원하는_양자화_형식여기서 `--outtype` 옵션은 양자화 형식을 지정하며, 예를 들어 `f32`, `f16`, `q8_0` 등을 사용할 수 있습니다. 양자화 형식에 따라 모델의 크기와 성능이 달라집니다. 저는 f32로 손실 없이 형식 변환을 시도했습니다.
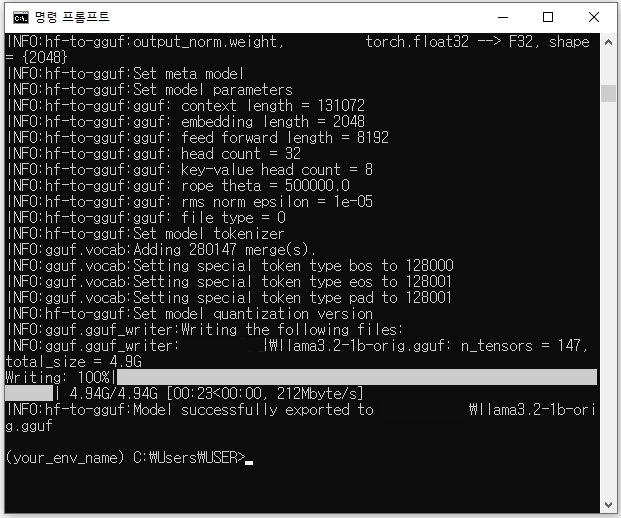
모델 변환은 성공적으로 끝났습니다. 이제 이 변환된 모델 gguf 파일을 Ollama에 이식하여 테스트해 보는 일만 남았네요. 여기까지 글이 길어졌으므로 이 부분은 다음 글에서 계속 정리해 보겠습니다.