오늘은 파인튜닝을 위한 준비 작업의 세 번째 이야기로, Transformers 라이브러리에 대해 이야기해 보려 합니다.
Transformers는 Hugging Face에서 발표한 오픈소스 라이브러리입니다. 이 라이브러리는 다양한 자연어 처리 작업을 수행할 수 있는 강력한 도구로 자리 잡고 있으며 많은 연구자와 개발자들의 관심을 끌고 있습니다. 오늘 이러한 자연어 처리(NLP) 기술이 필수적인 요즘 이와 관련한 기술의 핵심에 있는 Transformers에 대해 정리해 보려 합니다.
Transformers 라이브러리
Hugging Face의 Transformers 라이브러리는 다양한 자연어 처리 작업에 활용할 수 있는 모델과 도구를 한데 모아놓은 편리한 오픈소스 라이브러리입니다. 많은 사람들이 이 라이브러리를 주목하는 이유는 이곳에 포함된 모델들이 대부분 Transformer 기반이라는 점에 있습니다.
Transformer 모델은 기존에 자연어 처리에서 널리 사용되었던 순환 신경망(RNN)이나 합성곱 신경망(CNN)보다 훨씬 뛰어난 성능을 보여주며, 특히 긴 문맥 정보를 효율적으로 처리할 수 있다는 장점이 있습니다. Transformers 라이브러리는 다음과 같은 특징을 갖추고 있습니다.
- 다양한 사전 훈련 모델 제공: GPT 등 세계적으로 인정받은 여러 모델들이 사전 훈련된 형태로 제공되어, 사용자는 복잡한 모델 학습 과정 없이도 쉽게 성능 좋은 모델을 바로 활용할 수 있습니다.
- 사용자 친화적 API: 별도의 복잡한 설정 없이도 직관적인 코드 몇 줄로 모델을 적용할 수 있습니다. 이는 자연어 처리 초보자라도 손쉽게 고도화된 모델을 활용하게 하여 기술적 장벽을 크게 낮춥니다.
- 다양한 NLP 작업 지원: 감정 분석, 질문-응답, 번역, 텍스트 분류 등 다양한 언어 처리 작업을 단일 라이브러리에서 수행할 수 있어, 다양한 프로젝트에 유용하게 활용할 수 있습니다.
Transformers의 구조
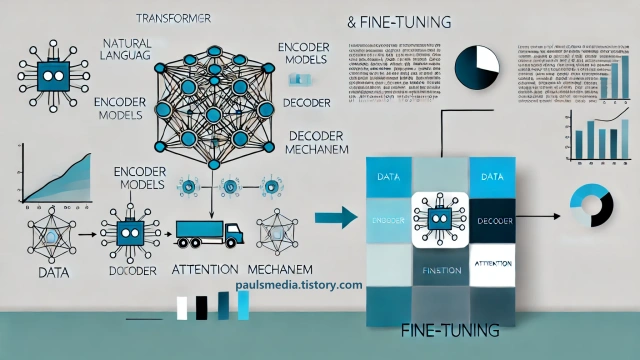
Transformers 라이브러리가 제공하는 모델들은 대부분 Transformer 아키텍처를 기반으로 합니다. Transformer 모델의 핵심 아이디어는 어텐션(Attention) 메커니즘으로, 문장 내 단어 간의 연관성을 효율적으로 파악하는 데 특화되어 있습니다.
이러한 Transformer 모델은 크게 인코더(Encoder)와 디코더(Decoder)로 나뉘는데, 인코더는 입력 문장 속 단어 사이의 관계를 분석해 이를 추상적이고 의미 있는 벡터 표현으로 바꿉니다. 반면 디코더는 인코더로부터 받은 정보를 바탕으로 새로운 문장을 만들어냅니다. 이러한 인코더-디코더 구조를 통해 모델은 긴 문맥을 동시에 처리할 수 있으며, 이는 기존 방식보다 훨씬 정교하고 세밀한 자연어 처리를 가능하게 합니다.
사용 사례 및 응용 분야
Transformers 라이브러리는 다양한 산업에서 여러 가지 응용 분야에 활용되고 있습니다. 몇 가지 주요 사용 사례는 다음과 같습니다.
- 자연어 이해(NLU): 고객 서비스 챗봇이나 음성 비서에서 사용되어 사용자 질문에 대한 정확한 답변을 제공합니다.
- 텍스트 생성: 소설이나 기사 작성, 광고 문구 생성 등 창작 작업에 활용됩니다.
- 번역 서비스: 언어 간 번역 작업에서 높은 정확도를 제공합니다.
- 의료: 환자 기록 분석 및 의학 논문 요약에 사용됩니다.
- 법률: 계약서 검토 및 법률 문서 요약 작업에 기여합니다.
이처럼 Transformers는 단순한 기술적 도구를 넘어 실제 문제 해결에 중요한 역할을 하고 있습니다.
Transformers 라이브러리 사용 방법
Transformers 라이브러리를 사용하는 과정은 생각보다 간단합니다. Python 환경이 준비되어 있다면 다음 명령어를 통해 쉽게 설치할 수 있습니다.
pip install transformers이후 Python 코드 상에서 다음과 같이 감정 분석 기능을 간단히 호출할 수 있습니다.
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
result = classifier("Hugging Face의 Transformers 라이브러리를 사용해보니 정말 편리하네요!")
print(result)위 예시 코드에서는 sentiment-analysis 파이프라인을 활용하여 텍스트에 담긴 감정을 분석하고, 그 결과를 화면에 출력합니다.
이렇게 단 몇 줄의 코드만으로도 고성능의 자연어 처리 모델을 직접 활용할 수 있습니다.
물론 프로젝트의 난이도나 규모에 따라 더 복잡한 설정이 필요할 수도 있지만, 기본적인 접근 자체는 매우 쉽고 직관적입니다.
하나 더 볼까요? Transformers의 여러 기능 중에 가장 중요한 기능 중 하나라면 파인 튜닝(Fine tuning)일 것입니다.
이러한 파인 튜닝을 실제 직관적으로 구현하는 방법을 아래의 예시를 통해 정리해 보겠습니다.
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# 데이터셋 로드
raw_datasets = load_dataset("imdb")
# 토크나이저 및 모델 로드
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 데이터셋 전처리
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding=True)
encoded_datasets = raw_datasets.map(preprocess_function, batched=True)
# 훈련 설정
training_args = TrainingArguments(
output_dir="./results", # 모델 저장 경로
evaluation_strategy="epoch", # 평가 주기 설정
learning_rate=2e-5, # 학습률
per_device_train_batch_size=8, # 배치 크기
num_train_epochs=3, # 학습 에포크
save_steps=10_000, # 모델 저장 빈도
save_total_limit=2, # 저장할 체크포인트 개수 제한
)
# Trainer 초기화
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_datasets["train"],
eval_dataset=encoded_datasets["test"],
)
# 모델 훈련
trainer.train()위 코드를 요약하자면,
- AutoTokenizer: 사전 훈련된 모델에 맞는 토크나이저를 자동으로 로드합니다.
- AutoModelForSequenceClassification: 텍스트 분류 작업에 적합한 모델을 로드합니다.
- TrainingArguments: 모델 훈련에 필요한 매개변수를 설정합니다. 예를 들어, 학습률, 배치 크기, 에포크 수 등을 지정할 수 있습니다.
- Trainer: 모델, 데이터셋, 훈련 설정을 통합하여 훈련 과정을 관리합니다.
- train(): 모델을 훈련시키는 메서드로, 설정된 데이터와 매개변수를 기반으로 훈련을 진행합니다.
이 코드를 통해 커스텀 데이터셋을 사용해 모델을 세부적으로 조정할 수 있습니다.
자연어 처리 기술은 여전히 빠르게 진화하고 있으며, Transformers 라이브러리 또한 새로운 모델 등장, 기능 개선, 학습 효율화 등의 과정을 거치며 계속 발전할 것에요.