이번 글에서는 최근 가장 핫한 3종류의 인공지능 언어 모델들을 비교해 보고자 합니다. 엔지니어 수준의 전문적인 리뷰가 아니라 일반인 관점에서 어떤 언어 모델을 사용하는 것이 더 편한까 라는 단순한 질문에서 시작해 보겠습니다.

챗GPT vs claude vs Llama 3.1
이번에 간단하게 비교해볼 인공지능 언어 모델들은 총 4가지입니다.(유료버전 1개 포함)
- 챗GPT-4o : OpenAI사의 GPT-4o 모델, 유료
- 챗GPT-4o mini : OpenAI사의 무료 모델
- claude 3.5 : Anthropic사의 Claude 3.5 sonnet, 무료
- llama 3.1 8B : Meta의 Llama3.1, 8B 모델, 무료, 오픈소스
llama 3.1 8B의 경우 챗GPT-3 정도의 성능을 나타낸다고 하던데, 지금은 챗GPT-3을 사용할 수 없으므로 챗GPT-4o mini로 비교해 보겠습니다. 또, 이번 비교 테스트에서 포함되지 못했지만, Llama 3.1 405B의 경우 챗GPT-4o와 견줄 만큼의 성능이 나온다고 하는데, 과연 실제 일반 사용자 입장에서 그렇게 느껴질지도 궁금합니다.
자, 우선 먼저 간단한 질문을 전달하고 어떻게 대답을 하는지 보겠습니다.
질문은:
RAG에 대해 알려줘
이 질문의 정답은 RAG (Retrieval-Augmented Generation) 대해 정확하게 설명하는 것입니다.
대답을 볼까요?
1. 챗GPT-4o

답변 내용에 이상이 없는지 검토도 하기 전에 우선 RAG의 풀네임부터가 다릅니다. RAG (Retrieval-Augmented Generation)을 원했으나, Recurrent Attention Generator로 대답을 하고 있습니다.
답변 내용을 살짝 검토해 봅니다. 전체 내용은 대략적으로는 질문했던 (Retrieval-Augmented Generation)에 대한 대략적으로 맞는 것 처럼 보이지만 역시 다른 대답을 합니다. 인공지능 언어 모델의 AI 할루시네이션 문제점이 나타나는 것일까요? Recurrent Attention Generator는 컴퓨터 비전 관련된 기술로 딥러닝과 관련된 기술이라고 하는데요, 답변 내용은 자연어 처리와 비전 처리를 마치 섞은 듯한 대답을 합니다. 마치 복사 편집하다가 오류가 난 듯한 대답을 한 것 같습니다.
유료 버전인데, 왜 이럴까요?
2. 챗GPT-4o mini
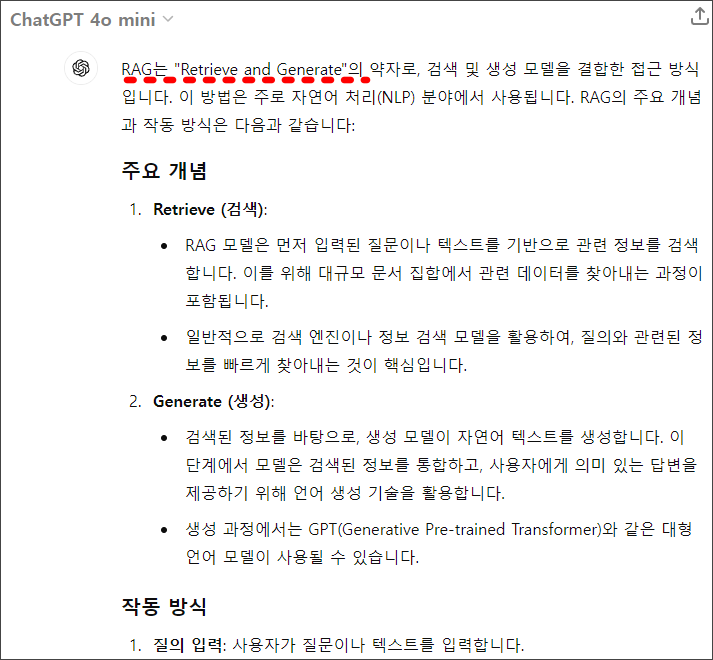
위 그림에서 볼수 있듯, 이번에도 RAG의 풀네임은 정확지 않았습니다. 하지만, 답변 내용은 앞서 챗GPT-4o처럼 혼재된 답변이 아니라 언어 처리와 관련된 대답을 하고 있습니다.
무료 버전인데, 이번 답변에서는 유료버전인 4o 보다 정확하게 대답했다고 볼 수 있겠네요.
3. Claude 3.5

챗GPT는 유료, 무료 버전 모두 RAG의 풀네임에 대해 오류가 있었지만, Claude는 정확하게 인식하고 대답을 하고 있습니다. 답변의 내용 역시 정확하게 서술하고 있네요.
4. Llama3.1 8B

Llama 3.1은 전혀 다른 대답을 합니다. 그리고 설명 분량도 앞의 3종류 보다 짧게 기술하고 있습니다. 용량이 적은 버전의 모델이라는 점에서 대답이 짧은 것은 문제 되지 않을 듯합니다.
재질문과 수정된 답변
답변이 부정확했던 모델들에게 재질문 합니다.
1. 챗GPT-4o
아래 같이 다시 질문을 합니다.
RAG의 풀네임이 "Recurrent Attention Generator" 이게 맞아?

재질문에 대해서는 정확하게 답변을 합니다. 이후 추가되는 설명도 역시 정확하게 서술을 합니다. LLM의 특징이라고 할만한 부분인지 모호하지만, 의도적으로 재질문은 "... 맞아?'라는 부정적인 의미를 포함하게 했더니, 이전 답변에 대한 부연 설명 없이 완전히 수정된 새로운 대답을 하는 것을 볼 수 있었습니다.
2. 챗GPT-4o mini
질문을 아래와 같이 다시 했습니다.
RAG의 풀네임을 다시 확인해 줘
부연 설명 없이 단순하게 다시 확인하라고만 했음에도 답변은 정확하게 대답합니다. 앞서 RAG의 풀네임만 오류가 있었으므로, 전체 대답은 수정해서 서술하지는 않네요.

3. Llama3.1 8B
라마 3.1은 RAG라고만 재질문을 했더니 계속 전혀 다른 대답을 하여 아래와 같이 풀네임을 제시하여 질문했습니다.
RAG(Retrieval-Augmented Generation)에 대해 알려줘

질문이 무엇인지 명확히 하여 재질문했음에도 정확한 대답은 하지 못하는 모습입니다. RAG의 가장 중요한 부분은 외부 검색에 있는데, 대답은 전혀 다른 의미를 전달하고 있네요.
정리하자면,
현재의 인공지능 언어 모델은,
- 유무료를 떠나서 답변 오류가 있을 수 있다.
- 비교한 모델 중 Claude 모델의 답변이 가장 정확하고 자연스럽다.
- llama3.1의 경우 전문 개발자 또는 관련 전공자가 아니라면 8B 모델보다 405B 모델을 사용하는 것이 이롭겠다.
정도가 될 것 같네요.
위와 같이 비교를 하는 것이 객관적이라 할 수는 없겠습니다만, 간단한 질문과 답변의 내용과 형태로만 보아도 현재 수준에서 한국어를 사용하는 일반인에게 가장 알맞은 것은 Claude가 아닐까 하는 생각으로 정리되는 것은 무리가 아닐 것 같습니다.
개인적으로도, 지금까지 챗GPT를 써 왔는데, Claude 유료 버전을 사용해 봐야겠네요.